

Expert materials
Stay tuned for the latest trends and updates in the IT industry. Learn the best practices and expert opinion on the software development and modernization from our technical specialists.
Latest article
Enterprise AI has entered a different stage. Another pilot project isn't automatically a cause for celebration.
Most organizations have already proved AI can create value somewhere in the business. The harder part is repeating that success across departments, products, and growing workloads. An assistant helping one customer service team is one thing. Supporting the entire organization with reliable, trusted information is another.
A useful way to evaluate enterprise AI readiness is to look beyond individual AI projects and assess how well the business can support AI as adoption grows. The five dimensions that follow provide a practical way to identify both strengths and gaps before they affect future AI initiatives.
Why AI readiness has become a business capability
Organizations often assume successful AI projects indicate they're ready for broader adoption. Experience suggests something different.
Imagine two manufacturers introducing AI assistants for predictive maintenance.
The first company connects equipment telemetry, maintenance records, service manuals, and work orders through modern APIs with clearly defined data ownership. Engineers spend their time improving recommendations because the underlying information is already available.
The second company owns similar data, though it's distributed across aging applications maintained by different business units. Documentation is incomplete. Data definitions vary between systems. Access requests require multiple approvals. Before the AI assistant can provide reliable answers, teams spend weeks preparing and validating information.
Both companies purchased similar AI technology.
Only one had the operational foundations to support it.
One successful AI implementation doesn't automatically translate into enterprise AI readiness. Recent industry data suggests many organizations are reaching the same conclusion as they expand AI across multiple business functions.
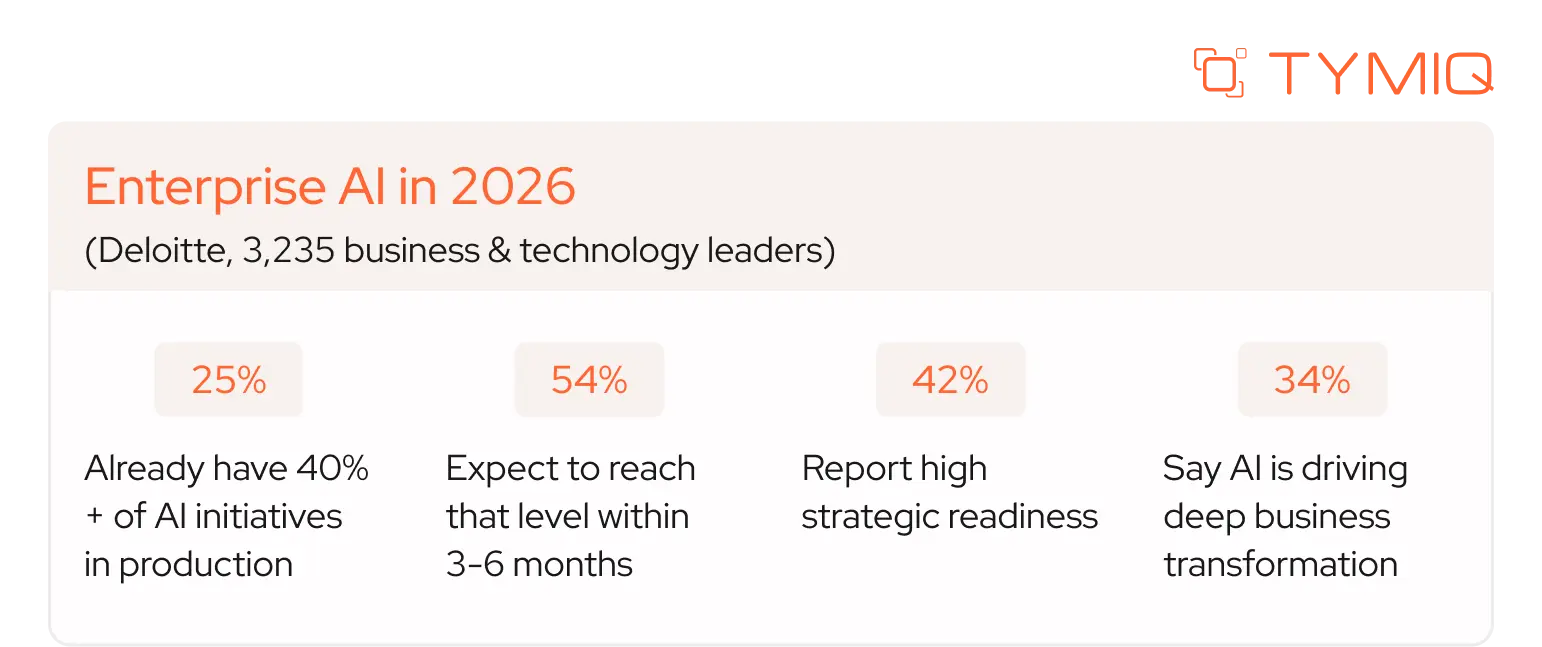
McKinsey reached a similar conclusion. Only 7% of companies report fully scaling AI across their organizations, and more than two-thirds of high-performing companies identify data as the primary barrier to broader AI adoption.
The biggest obstacles usually appear after the first AI pilot succeeds. Our recent piece on building AI-ready infrastructure explains why scaling AI requires much more than another successful use case.
A useful way to think about readiness is to compare what AI projects need before they can grow.
The distinction is subtle, though it has a significant impact on long-term AI adoption.
A retailer may already use AI to improve product recommendations and automate customer support. Those projects demonstrate business value.
The same retailer may still struggle to extend AI into pricing, supply chain planning, or finance because customer data is fragmented, legacy systems are difficult to integrate, or governance responsibilities are spread across multiple departments.
The organizations making the fastest progress with AI aren't always the ones deploying the newest models. They're often the ones that invested early in the capabilities surrounding those models, making every new AI initiative easier to deliver than the last.
What an AI readiness assessment looks for

Most organizations begin an AI initiative by evaluating technology. They compare models, estimate implementation effort, and prioritize use cases with the fastest business return.
An AI readiness assessment starts somewhere else.
The discussion usually begins with the systems AI will depend on every day. Can it retrieve information from existing applications without custom integrations? Are APIs consistent across business systems? Does identity management support secure access? Can AI retrieve the same customer record regardless of which department requests it?
Those questions often reveal more than another successful pilot ever could.
During an assessment, technical conversations quickly move beyond model selection.
An assessment may uncover overlapping APIs maintained by different teams, customer data stored under different schemas, legacy authentication services that cannot support modern AI applications, or integration layers that become bottlenecks as new AI services are introduced. None of those issues prevent an individual pilot from succeeding. They become much more visible once AI starts supporting multiple products or departments.
That explains why AI readiness is usually evaluated across several capabilities instead of a single maturity score.
At TYMIQ, we focus on five areas that consistently influence enterprise AI adoption.
Reliable AI depends on trustworthy data. Trusted data depends on consistent governance. Modern infrastructure becomes far more valuable when delivery teams can support it effectively.
Looking at only one area rarely explains whether an organization is prepared for enterprise AI, but looking at all five together usually does. Let’s examine them more closely.
1. Strategy
Only three in ten organizations say they're highly prepared to support AI from a technology standpoint, according to Microsoft. Those making the fastest progress have already connected AI investments to business priorities, modernization, and executive ownership.
The truth is, many organizations already have more AI ideas than they can realistically deliver. A readiness assessment helps determine which initiatives align with business priorities and which depend on stronger data, infrastructure, or governance before they can succeed.
One simple exercise often reveals how aligned the strategy really is. Ask several stakeholders to describe the purpose of the same AI initiative.
If engineering talks about improving developer productivity, operations focuses on reducing manual work, finance expects lower operating costs, and product leadership wants a better customer experience, the organization isn't working toward one outcome. Each team is measuring success differently. Projects rarely lose momentum because there aren't enough ideas. More often, they slow down because every stakeholder has a different definition of success.
For that reason, strategy discussions during a readiness assessment focus less on technology and more on business alignment.
Teams spend surprisingly little time talking about models, prompts, or vendors. Those decisions matter, though they only become meaningful after the organization has agreed on where AI should create value and how success will be measured.
Data
Data usually becomes the longest conversation in any readiness assessment.
Most organizations have plenty of information. The question is whether AI can reach it consistently.
Think about how a customer support assistant answers a simple question.
"What products does this customer own?"
The response may require information from a CRM platform, an ERP system, a product catalog, billing records, support tickets, and internal documentation. If those systems disagree, contain duplicate records, or use different customer identifiers, the assistant has no reliable answer to build from.
McKinsey's June 2026 research found that only 7% of organizations have fully scaled AI across the enterprise. More than two-thirds of high-performing companies identify data readiness as the primary constraint, prompting leading organizations to invest in governed, reusable data platforms instead of project-specific integrations.
An AI readiness assessment verifies data ownership, systems of record, integration paths, and the consistency of AI retrieval across enterprise systems.
Typical findings include:
These issues become much harder to ignore when AI starts supporting multiple teams.
Infrastructure
Infrastructure often becomes visible only after the first AI project succeeds.
A pilot may work well with a handful of users and one or two connected systems. Production environments introduce different requirements. AI services need reliable APIs, secure identity management, scalable compute resources, monitoring, and integration patterns that can support growing demand without creating operational bottlenecks.
This is where many organizations discover that AI adoption depends on architecture decisions made years before AI entered the roadmap.
A readiness assessment examines the technical foundation supporting AI, not the AI platform itself.
Typical questions include:
- Can existing applications expose business data through stable APIs?
- Can AI services authenticate using existing identity providers?
- Are integration platforms capable of supporting real-time AI workloads?
- Can infrastructure scale as AI usage grows across departments?
- Are AI services observable through existing monitoring and logging tools?
One useful way to visualize infrastructure readiness is to follow the path every AI request takes.
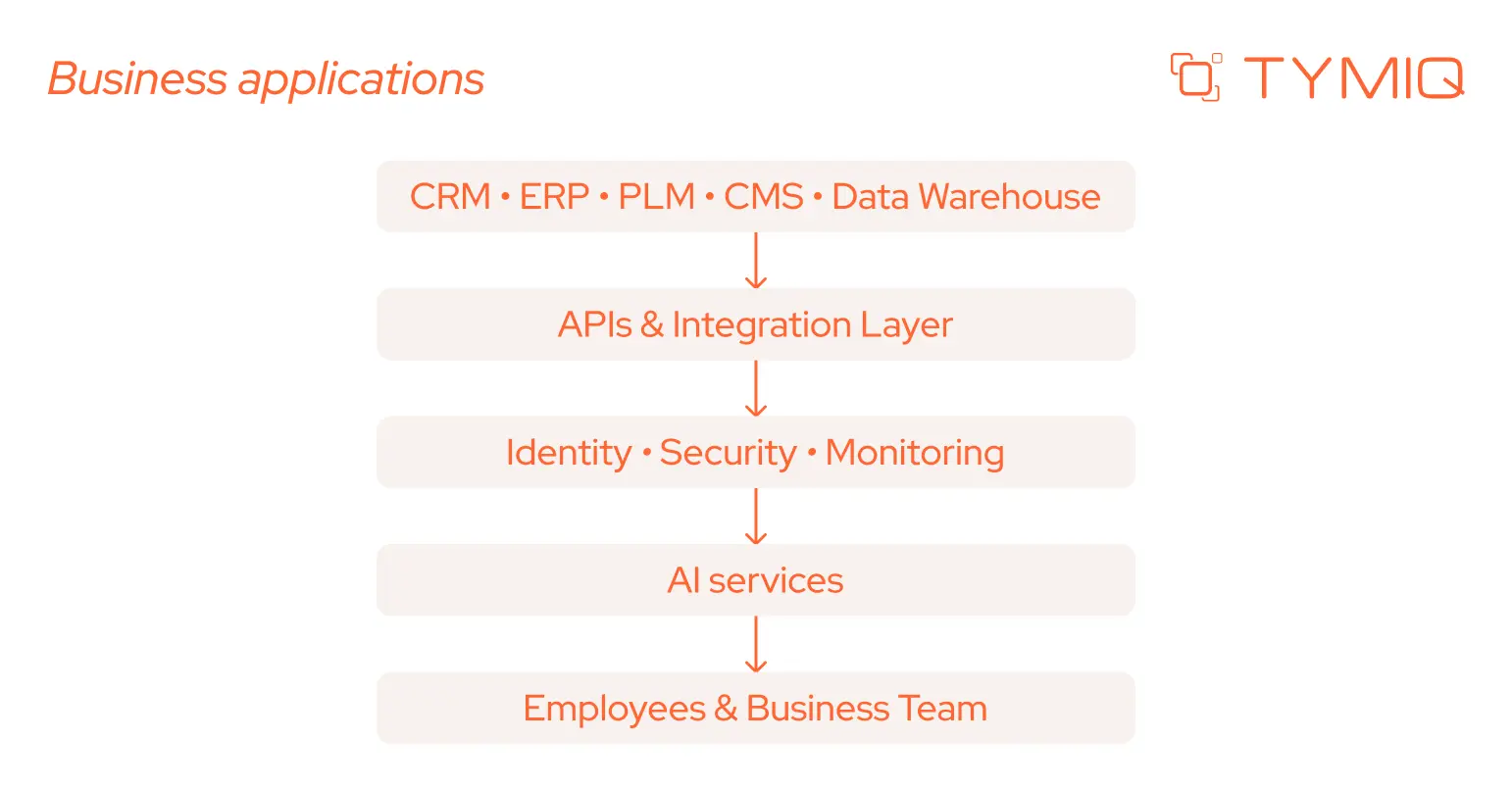
If one layer becomes difficult to extend, every new AI initiative inherits the same limitation.
Google Cloud's 2026 enterprise AI research found that more than 80% of organizations expect infrastructure changes to support the next generation of AI systems. AI investment is accelerating, though many technology environments were never designed to support AI workloads across the business.
Infrastructure readiness isn't measured by how modern the technology stack looks. It depends on whether existing systems can support another AI initiative with roughly the same effort as the previous one.
Governance
Governance usually enters the conversation later than it should.
The first AI pilot often has a small user group, carefully selected data, and close oversight from the project team. As adoption grows, the number of decisions requiring governance grows with it.
- Who approves new AI use cases?
- Who decides which business data AI can access?
- Who validates responses before they influence customer-facing processes?
- Who remains accountable after deployment?
Those questions rarely belong to engineering alone. That's why governance often determines whether AI stays a successful pilot or grows into an enterprise capability.
Deloitte notes that only 21% of organizations have a mature governance model for autonomous AI agents, even as most expect agentic AI adoption to accelerate over the next two years.
The report also found that organizations where senior leadership actively shapes AI governance achieve significantly greater business value than those treating governance as a technical responsibility. In other words, governance creates the conditions needed to scale it responsibly.
Technology can enforce access policies. Deciding who should have access, and under what circumstances, is a governance decision. The earlier those decisions are made, the easier it becomes to expand AI across the business with confidence.
Delivery
Launching an AI solution marks the beginning of a much longer operational lifecycle.
Business priorities evolve. Source systems change. New regulations appear. Models improve, and users quickly identify opportunities the original implementation never anticipated.
Someone needs to monitor performance, refine prompts and workflows, maintain integrations, respond to incidents, and decide which improvements deserve attention next. Without clear ownership, even successful AI solutions gradually lose momentum.
During a readiness assessment, delivery focuses on what happens after go-live. The objective is to determine whether AI can become part of everyday operations rather than another project that slowly fades into the backlog.
Organizations with mature delivery practices treat AI like any other business-critical system. They establish clear ownership, continuously monitor performance, and improve solutions as business needs evolve. That consistency makes each new AI initiative easier to deliver than the last.
AI readiness is measured by what comes next
Enterprise AI readiness isn't measured by the number of pilots, models, or AI tools an organization has deployed. It reflects how well strategy, data, infrastructure, governance, and delivery work together to support the next initiative.
One strong capability rarely compensates for weaknesses elsewhere. Modern infrastructure can't overcome fragmented data. Reliable data won't help if governance is unclear. A well-defined strategy still depends on delivery teams that can operate AI successfully after deployment.

Enterprise AI readiness framework: Evaluate your business in 5 dimensions

10 legacy modernization tasks AI can already automate, and 7 it still can't
The biggest modernization bottlenecks often appear long before anyone writes new code. Here's where AI is already changing the process, and where it still needs experienced engineers.
AI
Legacy modernization
Migration
The shift from AI pilots to AI-ready infrastructure: why early success doesn't guarantee scale
The hardest part of AI adoption often begins after the pilot succeeds.
Legacy modernization
Software maintenance
AI
Why legacy systems become an AI bottleneck: 7 reasons businesses struggle to scale AI
AI often struggles outside controlled environments. Learn which infrastructure issues quietly slow adoption and scaling.
Legacy modernization
Software maintenance
AI
What is AI modernization? Strategy, benefits and roadmap for 2026
Many businesses are ready for AI tools. Fewer are ready for AI at scale. See what modernization changes behind the scenes.
Legacy modernization
Software maintenance
AI


.svg)


