





If your cloud provider increases pricing next quarter, could your team move critical workloads within 30 days?
Most organizations cannot answer this question with confidence. Cloud adoption expanded across industries, but exit readiness did not follow at the same pace. Plans exist, but few teams validate them under real conditions.
The Flexera State of the Cloud Report shows that 87% of enterprises operate in multi-cloud environments, yet cost control and governance remain top concerns.
Multi-cloud increases flexibility in theory. In practice, it introduces more dependencies, contracts, and operational complexity. Teams believe workloads can move easily. When migration begins, constraints appear across data, infrastructure, and cost.
A cloud exit strategy is an operational capability. It requires tested processes, clear ownership, and measurable readiness – which we all would discuss in today’s dedicated piece.
Why cloud exit strategies fail
Cloud exit failure usually starts long before migration.
Systems grow around a single provider. Managed databases, identity systems, and messaging services became deeply integrated. These choices speed up early development. Over time, they reduce flexibility.
Cost becomes a barrier as well. Data transfer fees range from 0.05 to 0.12 dollars per GB, depending on provider and region. At scale, this limits movement.
The most common issue is a lack of testing. Teams define exit strategies but do not simulate them, so when migration begins, assumptions fail.
You can observe this during execution:
- Data transfers take longer than expected
- Services behave differently across environments
- Hidden integrations break workflows
- Rollback procedures are incomplete
Cloud exit fails when constraints are discovered too late, so let’s get to know the enemy.
3 integral components of the cloud exit toolkit
Most cloud exit discussions focus on tools or migration steps. In practice, successful exits depend on a small set of capabilities that determine whether migration is possible under real conditions.
These capabilities define how systems behave when you attempt to move them. If one of them is weak, the entire exit process slows down or fails.
A working cloud exit strategy relies on three areas:
- Data portability. Data must move across environments without loss, inconsistency, or extended downtime
- Infrastructure reproducibility. Systems must be recreated in another environment without manual rebuilding
- Observability across environments. Teams must see how systems behave before, during, and after migration
These areas are connected. Data movement affects infrastructure, which, in turn, changes affect system behavior. Without visibility, teams cannot detect or resolve issues during migration.
In many environments, one of these capabilities is missing or only partially implemented. This creates a situation where migration appears possible in planning but fails during execution.
Let’s examine each one of these areas in detail, including how teams assess readiness and what steps improve execution.
Data portability: the primary constraint
Data portability determines whether exit is feasible within a defined timeline.
Infrastructure can be rebuilt quickly. Data movement introduces delays and validation requirements. In production systems, these dependencies are often undocumented. Reporting tools, scripts, and integrations rely on direct access.
This creates three constraints:
- Transfer limitations. Large datasets require staged migration while systems remain active.
- Data consistency. Data must match across environments using validation processes
- Dependency mapping. All systems interacting with the data must be identified
In unprepared environments, teams only understand part of the data flow. During migration, unknown dependencies appear and delay progress. In prepared environments, teams map data flows early and test migration under real conditions.
Unprepared environments rely on assumptions, while prepared environments rely on validated processes. Check out these recommendations:
- Run full-scale export tests: export a production-sized database during off-peak hours and measure how long the transfer takes
- Measure transfer performance: simulate migration over your actual network to identify bottlenecks
- Document all data consumers: identify reporting tools or scripts that access the database directly
- Introduce abstraction layers: replace direct database queries with API calls
- Validate data integrity: compare row counts and checksums between source and target systems
Data portability defines the pace of migration. Without preparation, delays extend across the entire project.
Infrastructure as Code: recreating environments
Infrastructure as Code defines whether systems can be recreated outside the current provider without manual effort. This capability becomes critical during a cloud exit, when environments must be reproduced quickly and consistently under time pressure.
Recent guidance from Google Cloud highlights configuration consistency and automation as key factors in reliable deployments. Key observations include:
- Environments defined in code reduce configuration drift across deployments
- Automated provisioning improves consistency between staging and production
- Version-controlled infrastructure allows teams to track and audit changes
- Standardized configurations reduce dependency on individual knowledge
In many environments, adoption remains incomplete. Teams define core infrastructure in code but still rely on provider-specific services or manual adjustments. These gaps often remain hidden until migration begins, when differences between environments cause delays or failures.
The difference becomes clear during deployment.
In unprepared environments, deployments require manual corrections. Configuration details depend on individual knowledge, and results vary between environments.
In prepared environments, deployments run automatically from version-controlled definitions and produce consistent outcomes across providers.
To move from partial adoption to full reproducibility, teams need to standardize how environments are defined and validated. Check out a few practical actions:
- Define complete environments in code: describe networking, compute, storage, and access policies in Terraform instead of provisioning them separately
- Validate deployments across environments: deploy the same configuration in two cloud providers to confirm identical behavior
- Reduce provider-specific dependencies: replace a proprietary database service with a database that can run in multiple environments
- Store all configurations in version control: track infrastructure changes through Git and review them before deployment
- Automate validation: run automated checks to confirm services start correctly and connect to required dependencies
When these practices are in place, migration shifts from rebuilding systems manually to redeploying them in a controlled and repeatable way.
Recreating infrastructure is only part of the problem. Once the environment is ready, the next question is whether your workloads can operate inside it without hidden dependencies or environment-specific assumptions.
Why portable workloads fail during cloud exit
Many teams assume that once infrastructure is ready, workloads will move without issues. This assumption often breaks during execution.
Workload portability determines whether a cloud exit can move forward or stall. When portability fails, delays increase, costs grow, and rollback becomes more complex.
As a result, teams usually discover these issues only after migration begins, when systems run under real conditions. This is why workload portability requires dedicated attention in any cloud exit strategy. Recent research from Deloitte highlights that many organizations face challenges when relocating workloads due to hidden dependencies and environment-specific configurations.
Common failure scenarios include:
- Services cannot connect to databases due to network or authentication differences
- Authentication fails because access depends on provider-specific roles
- Background jobs or integrations stop working due to missing dependencies
- Performance drops due to changes in latency or storage behavior
It is important to point out that these issues are difficult to detect during development. They become visible only when workloads are executed in a new environment under production conditions.
The difference between assumed and actual portability becomes clear when teams attempt a controlled relocation of a single service.
In unprepared environments, deployment appears successful, but functionality breaks due to hidden dependencies.
In prepared environments, services run with consistent behavior because dependencies, identity, and configuration have been abstracted.
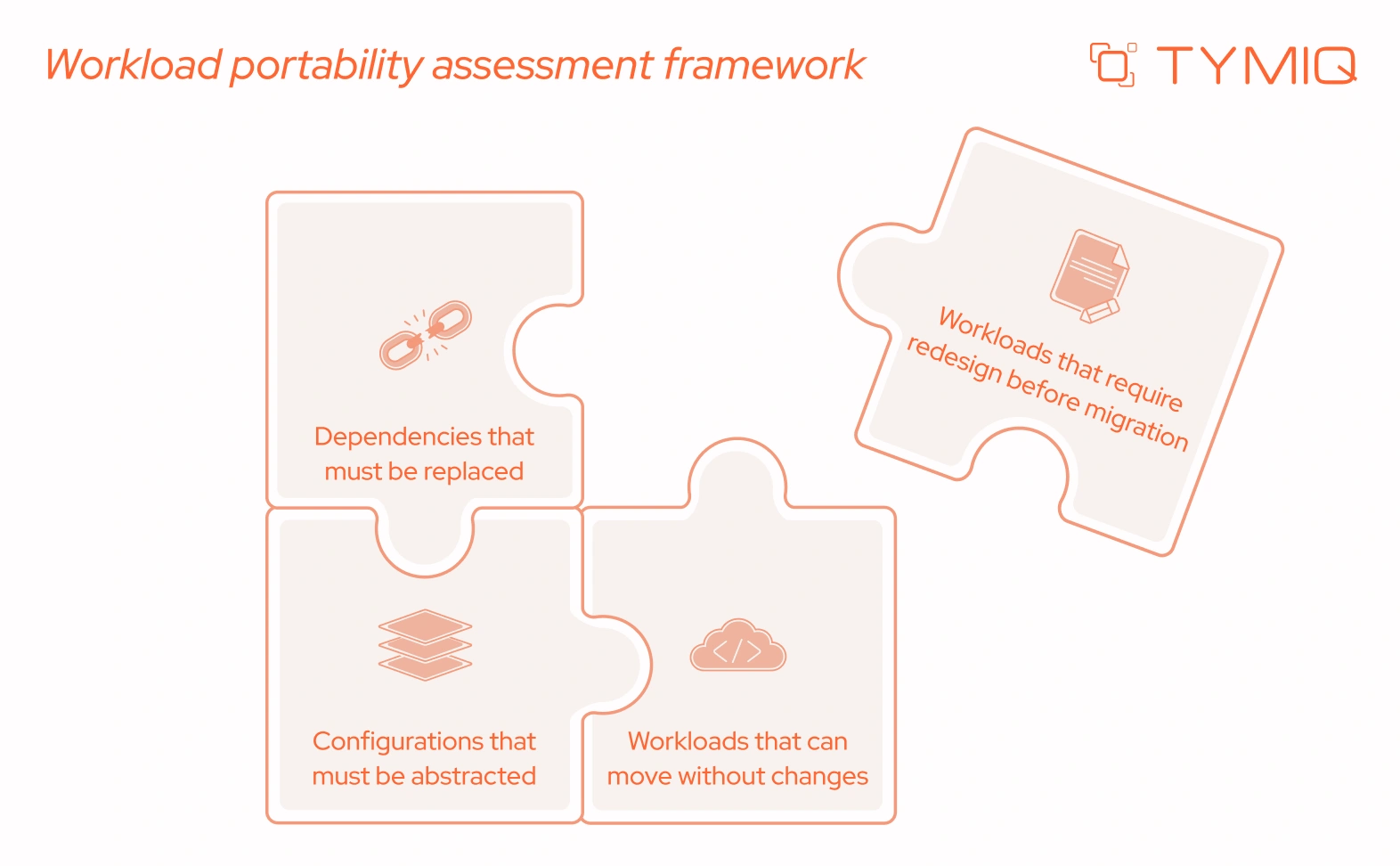
Over time, portability becomes a measurable capability instead of an assumption. This directly reduces migration risk and improves predictability during cloud exit.
Clear visibility into portability also changes how teams estimate effort and timelines. Once these constraints are understood, the financial impact of migration becomes easier to evaluate, which leads directly to the cost considerations discussed next.
The hidden cost of cloud exit
Cloud exit is often treated as a technical task. Cost shapes how far and how fast a migration can move forward. Many teams plan infrastructure changes in detail but overlook the financial impact of running systems under real migration conditions.
The cost challenge comes from multiple layers that appear at different stages of cloud repatriation and affect each other.
- Data transfer is the most visible cost. In practice, data is rarely moved once. Initial transfers fail validation. Incremental updates follow. Systems continue generating new data during migration. Each step increases total transfer volume.
- Engineering effort grows at the same time. Teams work with systems that include undocumented dependencies and environment-specific configurations. A service may work in staging but fail in production due to identity or network differences. Each issue requires investigation, fixes, and retesting.
- Parallel infrastructure adds another layer. To avoid downtime, teams run systems in both environments during migration. This includes compute, storage, and supporting services. Even short overlap periods can increase total cost.
- Performance impact introduces indirect cost. When services and data are split across environments, latency increases. For example, a backend moved to a new provider may still depend on a database in the original environment. Response times increase, and system behavior changes under load.
These cost factors do not appear separately. A delay in resolving one issue extends infrastructure overlap. Although most estimates are based on static assumptions, cloud exit (and a failed cloud migration as well) happens under changing conditions.
A common scenario illustrates this. A team plans to migrate a service within two weeks. During execution, authentication fails because access depends on provider-specific roles. Fixing this requires changes across multiple services. The migration is delayed. Both environments continue running, and costs increase across infrastructure and engineering time.
Without validation, these situations are not visible during planning.
How TYMIQ approaches cost modeling in cloud exit
Cost influences every migration decision. It affects which workloads move first, how phases are structured, and how long systems can run in parallel.
TYMIQ engineers treat cost estimation as part of migration validation. The focus is on measuring real conditions before committing to timelines.
In practice, this includes:
- Testing data transfer with validation overhead. We measure transfer time together with consistency checks and incremental updates.
- Estimating parallel run duration based on system dependencies. We calculate how long both environments must operate when integrations cannot move at the same time
- Mapping engineering effort to actual system constraints. We identify services with unclear dependencies and include time for investigation and fixes.
- Simulating performance impact. We test cross-environment communication to measure latency and its effect on system behavior
- Building scenario-based cost ranges. We define best-case, expected, and worst-case cost scenarios based on test results
Cloud exit is a financial process as much as a technical one. It requires the same level of validation as the systems being moved.
Cloud exit playbook
At TYMIQ, we know for sure: a stitch in time saves nine, so our team has prepared an operational guide that teams can use during planning sessions, architecture reviews, or pre-migration validation.
It can be useful at different stages. Some use it before defining a migration strategy. Others use it to validate readiness before moving critical workloads. In practice, it supports four core activities:
- Run the checklist before planning to identify gaps early
- Validate the runbook through controlled tests before production changes
- Use the scorecard to prioritize improvements across systems
- Repeat the process as systems evolve, and dependencies change
1. Cloud exit readiness checklist
This section is useful for engineering leaders, architects, and operations teams who need to assess whether their current environment can support a controlled migration. It is typically used at the earliest stage, before defining timelines or committing to an exit plan.
Use this checklist to determine whether your environment can support controlled migration.
- Data export tested using full production volume
- All systems interacting with data identified and documented
- Infrastructure fully defined in code and version-controlled
- Cost model includes transfer, compute, and temporary duplication
- Rollback process defined and tested under load
Additional recommendations:
- Validate export performance during peak and off-peak hours
- Confirm access permissions for data extraction across environments
- Identify regulatory constraints related to data movement
- Define acceptable downtime thresholds before testing begins
At this stage, teams often discover gaps that were not visible during planning. A data export may take longer than expected, or dependencies may appear across systems that were not initially considered. These findings shift the focus from assumptions to constraints. Once these constraints are clear, the next step is to define how migration will actually be executed.
2. Exit runbook
This section is useful for delivery teams and engineering managers responsible for executing migration steps. It is applied once readiness gaps are identified and teams need a structured way to perform migration without disrupting operations.
The runbook defines how migration is executed step by step. It should be precise enough to follow without interpretation.
Core components:
- Assigned roles for each stage of migration
- Sequenced migration steps with clear dependencies
- Communication plan for internal teams and stakeholders
- Defined rollback triggers and recovery procedures
Additional recommendations:
- Include timing estimates for each step based on test runs
- Define escalation paths for critical failures
- Document system states before and after each phase
- Align communication timing with business operations
When teams begin testing the runbook, differences between planning and execution become visible. Steps that seemed straightforward require coordination across multiple teams. Timing assumptions need adjustment. Some rollback procedures may need refinement. These insights help teams understand which systems are ready to move and which require further preparation.
3. Portability scorecard
This section is useful for architects and technical leads who need to prioritize migration efforts across multiple systems. It is applied after initial testing to evaluate which workloads can move safely and which require additional work.
Use this scorecard to evaluate how prepared each system is for migration.
- Can data be exported, transferred, and validated without manual intervention?
- To what extent does the system rely on provider-specific services?
- Can the system be redeployed in another environment without changes?
- Can performance and failures be tracked across environments?
Additional recommendations:
- Review each category with both engineering and operations teams
- Assign ownership for improving low-scoring areas
- Reassess after major system changes
- Link scorecard results to migration planning decisions
At this point, teams move from understanding constraints to making decisions. Some systems show high readiness and can be migrated early. Others require additional work before they can be included in the plan. This creates a sequence of actions instead of a single large migration effort, which leads directly into controlled execution.
4. Execution sequence
This section is useful for coordinating migration across teams and aligning execution with business priorities. It provides a structured order of actions based on validated readiness.
Identify gaps across data, infrastructure, and cost before defining timelines
Simulate migration using non-critical workloads and refine steps
Prioritize which workloads can move first based on readiness
Start with low-risk systems and expand gradually
Update the checklist and scorecard based on new findings
As execution progresses, new constraints and dependencies will appear. Teams refine their approach after each phase, improving accuracy and reducing risk. Over time, migration becomes a repeatable process instead of a one-time event.
In a nutshell
Cloud exit strategy defines how much control an organization has over its systems. It affects cost, resilience, and long-term flexibility.
The key points are consistent across environments:
- Data determines migration speed and complexity
- Infrastructure defines whether systems can be recreated
- Observability controls risk during transition
- Contracts define financial feasibility
- Testing reveals constraints before they affect production
Most teams assume readiness. Few validate it under real conditions.
If you want to evaluate your current environment, TYMIQ cloud architects can analyze your system, identify risks, and define a practical exit strategy based on your architecture and business requirements.
Schedule a quick non-binding conversation and get a clear plan for your cloud exit readiness.



.svg)


