

.png)



Large .NET migrations fail when you treat them as a framework upgrade or a clean rewrite, because both approaches assume the business can pause for “engineering correctness.”
Hybrid migration is the survivable alternative. You keep critical workloads running while replacing the system in slices. It works when you protect invariants (what mustn’t change) and evolve change surfaces (boundaries that are safe to modify). In this guide, you will get a phase model, a pattern selection matrix, and a per-slice artifact checklist so you can modernize without stopping delivery.
The 10-minute decision path
Answer these five questions. Then pick your starting pattern mix and the minimum controls before you move any traffic.
1. Can you route or intercept requests at the perimeter?
If yes, start with Strangler Fig. If not, lean on Branch by Abstraction.
2. Do you need strict behavioral equivalence, or “close enough” with tolerances?
If strict, plan Dual-run validation for the critical journeys. If tolerant, use progressive delivery with tight monitoring.
3. How risky is data coupling?
Shared database writes, stored procedures, and reconciliation needs push you toward Dual-run, CDC/outbox, and explicit drift detection.
4. Do compliance or data residency rules force hybrid infrastructure?
If yes, plan for runtime hybrid + infrastructure hybrid from day one. Treat it as one system operationally, not two systems politically.
5. What is your downtime tolerance?
Near-zero downtime favors Strangler + progressive delivery + rollback + observability baseline. Scheduled downtime lets you simplify controls and shorten the coexistence period.
Glossary and the mental model
Hybrid programs fail when people use the same words to mean different things. Fix the vocabulary first, then decisions become faster and less political.
Glossary. One-screen definitions you will reuse
Hybrid migration
A staged modernization where legacy and modern components run side by side for a period of time. You replace the system in slices, without stopping delivery.
Runtime hybrid
Two runtimes coexist. For example, .NET Framework services continue running while new services run on modern .NET.
Infrastructure hybrid
Two environments coexist. For example, on-premises stays for regulated workloads while cloud hosts new components or scale-out edges.
Slice
The smallest unit of functionality you can migrate independently without stopping the system.
Big-bang
A single cutover where you switch everything at once. High risk when uptime, compliance, and unknown dependencies matter.
Incremental migration
You migrate in small slices with clear boundaries, rollback, and evidence-based gates.
Contract stability
Interfaces remain stable for callers. Examples include URLs, message formats, WSDLs, API shapes, auth flows.
Behavioral stability
Outcomes remain stable. Same business result, same side effects, same edge-case handling, within defined tolerances.
Behavioral equivalence (with tolerances)
You define what “same” means. Example: “Totals must match exactly, but response time can vary by 15%.” This is essential for a hybrid because perfect parity everywhere is expensive and often unnecessary.
Dual-run (parallel stack)
Old and new implementations run in parallel. You compare outputs or outcomes before full cutover. Highest confidence, highest temporary cost.
Shadow reads
You read from the new path for validation, but serve responses from the legacy path. This reduces customer risk while you measure parity.
Dual-write
Both systems write. This is powerful and dangerous. You must plan drift detection and reconciliation from day one.
Drift and reconciliation
Drift is when the two systems disagree. Reconciliation is how you detect, explain, and correct that disagreement, ideally with repeatable scripts and “golden record” checks.
The spine of the approach. Invariants and change surfaces
You do not modernize everything at once. You protect what must not change, then you evolve what you can safely touch.
Invariants. What you treat as non-negotiable
- Correctness of critical workflows.
- Availability and downtime tolerance.
- Compliance boundaries and data residency.
- Security posture. Identity, auditability, least privilege.
Change surfaces. Where you can safely introduce new behavior
- Perimeter routing. Gateways, reverse proxies, API management.
- Façades and adapters that isolate internals.
- Non-core journeys. Reporting, search, read-heavy views.
- Modules with clear inputs and outputs and low data coupling.
How to think about every slice
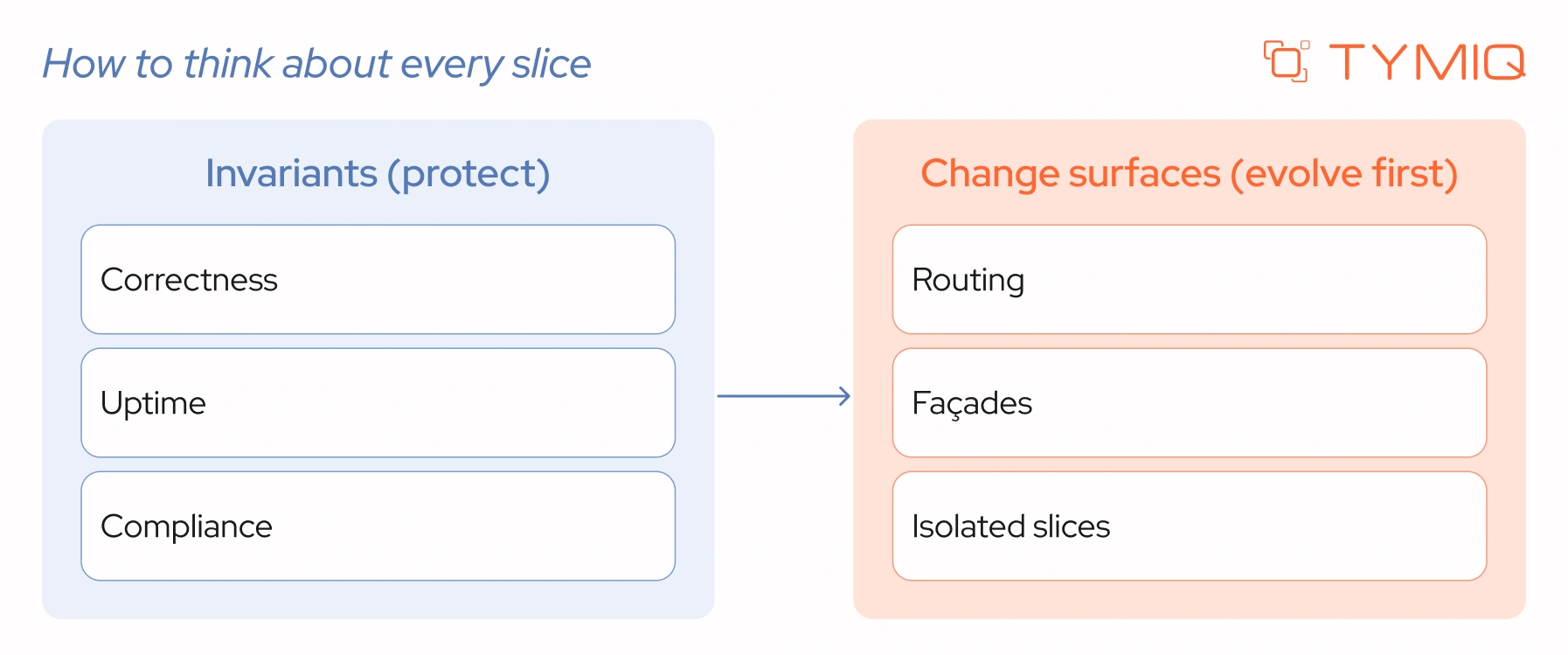
Two practical questions you should answer before any implementation
- What does equivalence mean for you, and where can you relax it?
If you do not define this, teams will argue forever about whether a slice is “done,” and you will never cut traffic safely. - Where are your safe change surfaces?
If you cannot route at the perimeter, you start inside the system using abstraction. If you can route, you start at the edge and pick low-coupling vertical slices.
Why “just upgrade the framework” fails and when hybrid is mandatory
A successful build does not guarantee a safe production system. In large .NET estates, most serious failure modes exist beyond what the compiler can detect.
Framework upgrades often fail because enterprise systems embed critical behavior in infrastructure, identity providers, data contracts, network boundaries, and operational processes. These elements form implicit agreements that are rarely visible in source code alone. When those agreements shift, the application may still start and respond to requests, yet its behavior no longer aligns with expectations.
The upgrade fallacy (enterprise tells)
If you recognize several of these signals, a big-bang upgrade is already high risk.
- System.Web or IIS coupling. WebForms lifecycles, HTTP modules, machineKey behavior, and hosting assumptions are not portable contracts.
- Identity tied to environment. AD groups, service accounts, and legacy auth logic often behave differently once hosting or runtime changes.
- Non-web workloads matter. Windows Services, batch jobs, file shares, and schedulers rarely show up in CI failures, but they break production flows.
- SQL Server gravity. Stored procedures, permissions, replication, and reporting create tight coupling that survives any framework retarget.
- Low observability zones. The least tested areas. Auth, async flows, data writes. Are where upgrades fail silently.
When hybrid is the best or only option
Hybrid migration is mandatory when at least one of the following is true:
- Downtime is unacceptable.
- Regulated or sensitive workloads must remain on-premises.
- Legacy dependencies block a direct port.
- Feature delivery must continue during migration.
Practical guidance
- Near-zero downtime required.
Start with Strangler at the perimeter, add progressive delivery, and establish rollback and observability before moving traffic. Use dual-run only where correctness must be proven. - Downtime tolerable.
You can simplify controls and shorten coexistence, but you still need explicit parity definitions and rollback paths.
When hybrid is not worth it
Small, isolated systems with low blast radius and clean boundaries are often better served by a direct migration or replacement.

Start safely. Phase 0 readiness audit and picking the first slice
Hybrid migrations fail early when teams rush into implementation without shared facts. Phase 0 exists to replace opinions with artifacts. It is short, explicit, and non-negotiable.
Phase 0 readiness audit (what you must produce)
This is not documentation for its own sake. Each artifact answers a decision you will otherwise argue about later.
Dependency map
- NuGet packages, third-party libraries, OS and Windows-only dependencies.
- Flag unsupported, abandoned, or version-locked components.
Integration contract map
- APIs, WCF endpoints, message queues, file drops, batch interfaces.
- Identify consumers you do not control.
Data gravity map
- Who owns which tables?
- Read vs write paths.
- Latency and replication constraints.
Compliance boundaries
- What must stay on-prem.
- Audit, logging, retention, and access constraints.
SLO baseline
- Key business journeys with current latency, error rate, availability.
- This is your parity reference, not a future goal.
Risk register
- Top risks, mitigation approach, and named owner for each.
If any of these are missing, you are not ready to migrate a slice.
Decision checkpoints
Before choosing where to start, answer three questions clearly.
- Can we intercept at the perimeter?
If yes, start at the edge. If not, prepare internal abstractions. - Where do we need strict behavioral equivalence?
Payments, compliance, and core data flows usually require it. Reporting and read paths often do not. - Where can we introduce an abstraction safely?
Look for seams with clear inputs and outputs, not “important” code.
These answers determine your initial pattern choice. Strangler, Branch by Abstraction, or Dual-run.
First slice selection

Your first slice proves the model. It is not where you show off.
Good first slices
- Reporting or search edges.
- Authentication or token façade.
- One WCF endpoint routed through a gateway.
Bad first slice
- The hardest core domain “to get it over with.”
First-slice charter (minimum)
- Scope and success criteria.
- Parity definition.
- Rollback plan.
- Data touchpoints.
- Cutover gate and owner.
If you cannot roll the slice back safely, it is not the first slice.
The goal of Phase 0 is simple. Reduce unknowns before you introduce risk. Once this is done, hybrid stops being an abstract strategy and becomes an executable plan.
Pattern toolkit and selection matrix
Hybrid migration works only when patterns are treated as decisions with prerequisites, failure modes, and exit signals, not as generic best practices. Most large programs use more than one pattern. The mistake is picking them too late, or applying them everywhere.
Strangler Fig. Routing and incremental replacement

When to use
Use Strangler when you can intercept requests at the perimeter. HTTP endpoints, APIs, UI routing, or message ingress points are ideal candidates.
What it gives you
- Contract stability for consumers.
- Incremental replacement without stopping the legacy system.
- Early wins on visible, high-value functionality.
Typical failure modes
- The façade becomes a bottleneck.
- Auth or identity decisions diverge between old and new paths.
- Hidden dependencies leak through routing boundaries.
Exit signals
- Defined journeys are fully served by the new path.
- Parity metrics meet thresholds over an agreed window.
- Legacy endpoints are decommissioned deliberately, not abandoned.
Branch by abstraction. Replacing internals safely
When to use
Choose this pattern when routing is not possible and you must replace deeply coupled internals. Payments, authorization logic, and integration adapters are common candidates.
What it gives you
- Behavioral stability during change.
- Gradual replacement without a “flag day.”
- Rollback via feature flags.
Typical failure modes
- Dual implementations linger indefinitely.
- Feature flag sprawl with no retirement plan.
- Equivalence is never defined clearly enough to cut over.
Exit signals
- Old implementation removed.
- Flags retired.
- Metrics stable for a defined period.
Dual-run. Parallel stack for validation

When to use
Dual-run is justified when correctness is non-negotiable. Compliance-heavy workflows, financial calculations, and data migrations often require it.
What it gives you
- Highest confidence through side-by-side validation.
- Evidence-based cutover decisions.
Typical failure modes
- Cost explosion from prolonged parallel runs.
- Dual-write drift without reconciliation.
- Operational overload.
Exit signals
- The equivalence window passed.
- Reconciliation is clean.
- Cutover executed and old path disabled.
Pattern selection matrix (decision view)
Important rule
Most enterprise migrations combine patterns. For example, Strangler at the edge, Branch by Abstraction inside, and Dual-run only for the most critical slices.
Your per-slice artifact pack
Before moving traffic for any slice, you should have:
- Slice charter.
- Parity definition.
- Rollback plan.
- Dashboard link.
- Runbook.
- Decommission plan.
If one of these is missing, the slice is not ready.
The two hard parts that decide success. Data and identity/security
Most hybrid programs don’t fail on routing or services but where state and trust live. Data and identity cross every boundary, amplify small mistakes, and punish ambiguity.
These are your first-class design problems.
Data in hybrid. The real coupling

Data is the strongest force holding legacy systems together. In hybrid, you are not “moving data.” You are managing coexistence until you can stop.
Shared database reality
Shared SQL Server is common in early phases. It reduces risk short term, but increases coupling long term. Treat it as temporary, with an exit plan.
Coexistence patterns you must choose explicitly
- CDC + outbox. Capture changes once, propagate safely, avoid tight sync.
- Backfills + idempotency. Assume retries, duplicates, and partial failure.
- Shadow reads. Validate new paths without serving users from them.
- Dual-write (carefully). Only with drift detection and reconciliation from day one.
Schema evolution rules
- Expand first, contract later.
- Backward-compatible columns and defaults.
- Versioned views for legacy consumers.
- No destructive changes without a cutover gate.
Cutover checks that actually work
- Sampling with known “golden records.”
- Automated reconciliation scripts.
- Clear thresholds for acceptable drift, not gut feeling.
Identity and security bridging
Identity inconsistencies are the fastest way to lose trust. In a hybrid setup, authentication decisions should be made once and applied consistently everywhere, even if execution is split across different environments.
Common reality
- Legacy auth is often environment-bound.
- Modern services expect tokens, claims, and explicit trust boundaries.
- Mixing models without a plan creates silent security gaps.
Bridging patterns that scale
- Token gateway in front of legacy systems.
- AD or Entra hybrid with clear authority boundaries.
- Service principals for service-to-service calls.
- Explicit claim mapping and rejection rules.
Operational security that must remain invariant
- Central secrets management.
- Certificate lifecycle and rotation.
- Audit trails across the boundary.
- Least privilege, reviewed regularly.
Micro-artifacts you should have
- Data coexistence plan with reconciliation scripts.
- Auth blueprint showing trust boundaries.
- Secret rotation runbook.
- Access review cadence and owner.
Run hybrid as one system. Delivery, observability, ownership
Hybrid fails when legacy and modern parts are operated as separate worlds. From day one, you must run them as one system with one operating model. This section is about discipline, not tooling.
Delivery discipline. CI/CD in hybrid
In hybrid, “one pipeline” does not mean one server. It means one promotion model and one source of truth.
What unified delivery actually means
- The same build logic for legacy and modern components.
- Immutable artifacts promoted across environments.
- Explicit versioning and provenance rules.
- No manual production changes outside a break-glass procedure.
What usually goes wrong
is that teams split their pipelines by environment: on-premises uses one process, while the cloud relies on another. As a result, hotfixes are applied on only one side, dependencies begin to drift, and over time rollback turns into little more than guesswork.
Minimum safeguards
- Shared pipeline templates repository.
- Pinned dependencies policy.
- IaC parity with drift detection.
- Environment parity checklist before promotion.
%20in%20the%20Cloud.webp)
Observability. System truth across boundaries
Hybrid architectures multiply blind spots, as latency travels across multiple networks and asynchronous workflows span different runtimes. At the same time, ownership becomes fragmented, making it harder to maintain clear responsibility and visibility across the system.
Baseline you need before moving traffic
- Correlation IDs propagated everywhere.
- Distributed tracing across old and new paths.
- SLO dashboards by business journey, not by service.
- Alerts on backlog growth, dead letters, and end-to-end duration.
Common failure pattern
Each side looks healthy in isolation. The system fails in between. Without unified signals, teams argue instead of diagnosing.
Operating model. Prevent “not my system”
Hybrid introduces ambiguity unless ownership is explicit.
Team topology that works
- Platform team. Owns pipelines, observability, and shared controls.
- Product teams. Own slices end to end.
- Migration-enabling team. Removes blockers and standardizes patterns.
Operational rules
- Clear on-call ownership across the boundary.
- Shared runbooks for hybrid incidents.
- Named cutover commander for migration events.
Minimum viable hybrid controls (MVC)
Before treating hybrid as safe, you should have:
- Proven rollback.
- Correlation IDs everywhere.
- One promotion model.
- Parity gates per slice.
- Named owners and on-call rotation.
Controls, gates, and proof of progress
Hybrid migration reaches an impasse when progress is subjective. In this section, opinion is replaced by facts. You define what “done” means, measure it consistently, and only remove the obsolete when the facts allow it.
Exit gates. What “done” actually means
Every slice needs explicit exit gates before traffic increases or legacy code is removed. Without them, coexistence becomes permanent.
Minimum exit gates
- Availability. Meets or exceeds baseline over an agreed window.
- Errors and latency. Within defined deltas versus legacy.
- Behavioral parity. Matches the agreed definition of equivalence, including tolerances.
- Security sign-off. No new critical findings. Audit trails intact.
- Operational readiness. Dashboards, alerts, runbook, and on-call ownership in place.
- Decommission plan. Clear steps and owner to retire the old path.
If a gate is not met, you do not argue. You stop and fix.
Scorecard and 30 / 60 / 90-day outcomes
Use a single scorecard across legacy and modern paths. Fragmented metrics hide risk.
Scorecard dimensions
- Technical. Parity defects, reconciliation errors, data drift.
- Operational. Incident rate, MTTR, change failure rate.
- Delivery. Deployment frequency, lead time for change.
- Business. Cost trend, customer-facing impact, throughput.
What “good” looks like
- 30 days. Phase 0 complete, first slice live behind routing, rollback proven.
- 60 days. Reusable templates, stable parity metrics, fewer incidents in touched areas.
- 90 days. Multiple slices migrated, measurable ops improvement, legacy scope shrinking with intent.
Progress is measured by reduced risk and increased confidence, not by lines of code moved.
Top failure modes and the control that prevents each
Hybrid failures are predictable. Each has a corresponding control.
- Deployment drift. Prevented by a unified pipeline and immutable artifacts.
- Silent degradation. Prevented by end-to-end observability and correlation IDs.
- Endless coexistence. Prevented by explicit exit gates and decommission plans.
- Data inconsistency. Prevented by reconciliation scripts and drift thresholds.
- Auth divergence. Prevented by a single decision point for identity.
- Flag sprawl. Prevented by retirement criteria tied to exit gates.
- Ownership gaps. Prevented by named owners and on-call clarity.
If a failure mode has no control, it is not a risk. It is a future incident.
End-to-end example. ATC-IDS (mission-critical hybrid)
Constraint. No downtime, heterogeneous environments, regulated operations.
Risk. Single cutover could break live ATC workflows.
Decision. Parallel hybrid migration with explicit parity checks.
Guardrails. Unified delivery, shared observability, per-slice exit gates.
Result. Modernization progressed without stopping operations, with evidence-based cutovers instead of assumptions.
Conclusion. Hybrid migration is a discipline, not a compromise
Hybrid migration works when it is viewed as a temporary operating model with rules, rather than as an undefined middle ground between the old and the new.
Successful programs have three common characteristics. They clearly protect invariants. Then they introduce changes only through controlled surfaces. Finally, they demonstrate progress with objective checkpoints before removing anything old. When these disciplines are in place, hybridization becomes a way to move faster with less risk, rather than slower with more complexity.
The goal is not “perpetual hybridity.” The goal is survivable modernization with measurable progress, where each step reduces risk, improves operability, and consciously reduces legacy.
If you recognize some of the symptoms described in this guide, like hidden dependencies, protracted updates, fear of transition, constant debates about readiness, your problem is unlikely to be a lack of tooling. More often, it reflects the absence of a clear operating model that defines how change is introduced and governed.
How TYMIQ helps
TYMIQ supports enterprise teams at exactly this point. We start with a Phase 0 readiness audit, define invariants and change surfaces, select the right pattern mix, and help execute hybrid migration without stopping the business.
If you need a clear, defensible plan for modernizing a large .NET estate under real constraints, let’s talk.





.svg)


