





Building Spring Boot microservices often begins with a straightforward goal. Teams want systems that scale more easily, recover faster, and support independent deployments. In enterprise environments, microservices also help engineering teams work more autonomously by separating ownership across domains.
Production environments introduce a different set of constraints.
Distributed systems create new operational risks. One delayed dependency can increase latency across multiple services. Retry logic can amplify traffic during incidents. Monitoring becomes harder once requests travel through dozens of services. Reliability moves beyond infrastructure and becomes an architecture concern.
This explains why many organizations underestimate what high availability means in practice. Running Spring Boot microservices at scale takes more than Kubernetes clusters and horizontal scaling. Stability depends on how services behave during failures, how dependencies recover under load, and how systems isolate problems before they spread.
Teams working on business-critical systems often learn this through production incidents. Microservices solve real problems, though they also introduce new operational risks as systems grow.
Here’s what we learned building systems where uptime could not become an afterthought.
Why high availability becomes harder in microservices
Microservices solve several problems found in monolithic systems. Teams can scale individual services, deploy components independently, and reduce release bottlenecks across engineering groups. In large enterprise systems, those advantages often support faster delivery and clearer ownership.
Distributed systems introduce more moving parts.
A monolith runs inside one process, which limits network-related failures and simplifies debugging. Spring Boot microservices rely on communication between APIs, caches, databases, queues, service discovery layers, and infrastructure components. Each dependency introduces another potential point of failure.
Consider a checkout workflow in an e-commerce system. A request may contact pricing, inventory, payment, fraud detection, shipping, and customer profile services before completion. One slow dependency increases latency for everything upstream. Timeout configurations start to matter. Shared thread pools begin filling. Retry traffic increases pressure at the same moment services struggle to respond.
Production failures rarely begin with a complete outage. Small delays spread gradually.
This becomes easier to understand when looking at how failures typically propagate across distributed systems.
Architects evaluating a transition to Spring Boot enterprise systems often focus on deployment flexibility and scalability. Those benefits matter, though operational complexity grows at the same time. High availability becomes harder because failures travel across boundaries between services, infrastructure, and external systems.
This creates an important architectural question:
Several lessons stood out after building high-availability systems.
Lesson №1: Design for failover before traffic arrives
Infrastructure failures happen. Services restart unexpectedly. Nodes disappear. Availability zones become unstable. Systems recover more quickly when failover paths already exist before production traffic increases.
Many teams postpone failover planning until outages happen. Recovery becomes harder once dependencies grow and services become tightly connected.
Reliable Spring Boot microservices assume infrastructure instability from the beginning.
Failover involves more than adding service replicas. Teams need health-aware routing, predictable failure detection, and workloads capable of recovering without manual intervention. Stateless services simplify recovery because replacement instances can start without hidden dependencies or local state restoration.
Spring Boot provides useful operational foundations through Spring Boot Actuator. Health endpoints expose service readiness and application health, which helps orchestration layers route traffic away from degraded instances. In Kubernetes environments, readiness probes determine whether traffic should continue reaching a service, while liveness probes help restart unhealthy containers.
This distinction matters more than many teams expect.
Some teams expose a basic /health endpoint without differentiating readiness from liveness states. Kubernetes continues routing requests to services experiencing downstream dependency issues because the infrastructure sees a healthy application process even though business functionality has degraded.
A payment service offers a useful example. The application process may stay alive during a database issue, though transactions fail because payment storage becomes unavailable. A readiness probe reflecting dependency health prevents traffic from reaching degraded services.
Timeout budgets also influence failover behavior.
Services responding slowly often cause more operational damage than services failing quickly. Slow degradation increases uncertainty. Requests accumulate, threads stay occupied longer, and upstream services continue waiting for responses that may never arrive.
Teams building high-availability Spring Boot enterprise systems often reduce timeout windows to encourage faster recovery and cleaner failover behavior. Shorter failure detection times reduce resource exhaustion during incidents.
In one enterprise environment, redundant workloads prevented regional service disruption because traffic was rerouted automatically after infrastructure instability appeared. Recovery happened quickly because failover assumptions already existed inside the architecture.
The lesson became difficult to ignore:
Lesson №2: Graceful degradation protects core functionality
Availability does not always mean complete functionality.
Many teams approach resilience as an all-or-nothing problem. Either everything works or the platform fails. Production systems often require a more practical approach.
Users rarely need every feature available during incidents.
An e-commerce system may continue processing orders even if recommendation services become unavailable. Inventory synchronization may tolerate short delays. Analytics dashboards can be updated later without affecting customer-facing workflows.
These tradeoffs influence uptime more than teams expect.
Graceful degradation allows systems to continue operating during dependency failures by reducing functionality temporarily. Teams decide which workflows deserve priority and which features can tolerate reduced accuracy, cached responses, or delayed processing.
This becomes particularly valuable in systems with strict uptime expectations.
For example, logistics platforms often prioritize shipment visibility and order creation during disruptions. Supporting systems such as reporting or recommendation engines may receive lower priority. In financial systems, transaction processing typically takes precedence over secondary features.
Several technical approaches support graceful degradation in Spring Boot microservices:
- cached responses for non-critical requests
- fallback methods for degraded dependencies
- feature toggles during incidents
- delayed asynchronous processing
- temporary read-only operating modes
Resilience4j became a common choice because fallback handling could remain close to business logic without spreading error-handling complexity across services.
A practical example helps explain this tradeoff.
A pricing service experiencing latency during peak traffic may still return cached product prices rather than blocking checkout completely. Customers continue placing orders even though pricing and freshness are temporarily reduced.
This type of decision depends on business priorities.
Teams need to define acceptable degradation levels before incidents happen. Otherwise, systems attempt to preserve every dependency equally, which increases operational risk under load.
Enterprise systems built for companies such as Swissphone and Conrad reinforced this point repeatedly. Systems serving business-critical workflows benefit when teams identify essential capabilities early and design around failure scenarios.
Lesson №3: Retries help systems recover until they overload them
Retry logic looks simple during development. A downstream request fails, so the service tries again.
Production systems behave differently.
Retries increase pressure during incidents and often contribute to wider failures when applied without limits. One slow dependency can trigger exponential traffic growth across upstream services.
Consider a payment service calling a fraud detection API. Latency increases because of temporary infrastructure instability. The payment service retries aggressively. Traffic multiplies. Thread pools begin filling. Downstream systems experience higher pressure precisely when recovery capacity decreases.
Temporary instability becomes a broader outage. Therefore, a retry amplification becomes one of the most common reliability issues in Spring Boot microservices.
Several microservices best practices that Java teams follow help reduce this risk:
- bounded retry limits
- exponential backoff
- randomized retry intervals
- timeout budgets between services
- idempotent request handling
- dependency-specific retry policies
Timeout coordination often creates reliability problems in Spring Boot microservices long before teams notice them. A service failing after three seconds brings limited value if upstream services continue waiting twenty. Long timeout chains increase thread exhaustion, reduce throughput, and make recovery slower during incidents.
Thread pool isolation becomes important for the same reason. Shared executors across workloads allow slow external dependencies to block threads needed by unrelated APIs. One unstable integration can affect endpoints with no direct dependency on the original failure. Dedicated executors reduce this spillover and improve system behavior under load.
Circuit breakers help contain retry amplification by pausing requests to degraded dependencies after failure thresholds are reached. Retry policies also benefit from dependency-specific tuning. Payment authorization may justify bounded retries with short timeout budgets. Reporting APIs often benefit more from failing fast. External services with inconsistent latency usually require stricter retry limits than internal dependencies.
Lesson №4: Cascading failures spread faster than teams expect
Most outages begin with a small issue.
A database query slows down. A cache misses more frequently than expected. One service experiences latency because of infrastructure contention. Teams often expect isolated failures. Distributed systems tend to behave differently.
Dependencies continue sending traffic even when services struggle.
A common failure sequence looks familiar in Spring Boot enterprise environments:
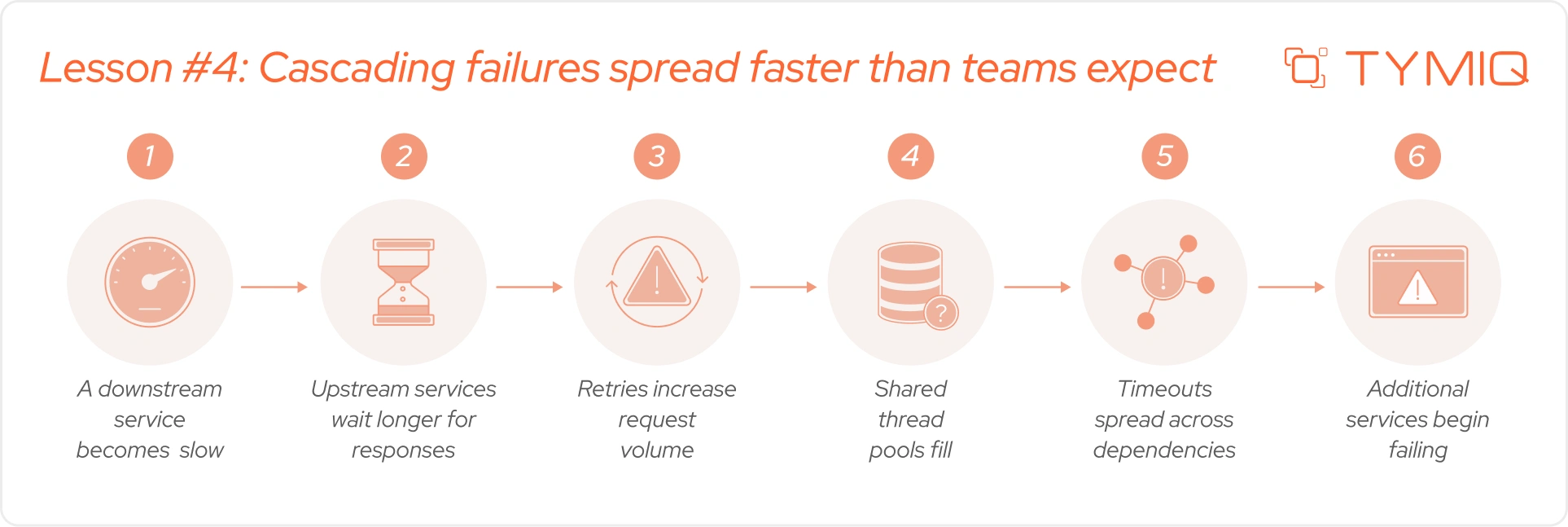
Recovery becomes harder because several systems compete for limited resources at the same time.
This explains why failure containment deserves more attention in Java microservices architecture. Teams building high-availability systems focus on limiting how far failures travel across dependencies.
Several resilience approaches consistently improved stability in production environments.
Circuit breakers prevent repeated requests to degraded services after failures cross a threshold. Once a dependency becomes unstable, traffic pauses temporarily and fallback behavior takes over. Recovery becomes easier because overloaded services receive time to stabilize.
Bulkheads isolate workloads from each other. Teams working with Spring Boot microservices often discover that shared executors become reliability risks under load. External integrations block threads longer than expected, and unrelated APIs begin slowing down.
Dedicated thread pools reduce this spillover.
For example, payment processing and reporting workloads should not compete for the same execution resources. An overloaded reporting service should not affect revenue-generating workflows.
Queue buffering also helps contain failures.
When traffic spikes unexpectedly, asynchronous queues absorb temporary pressure and smooth out processing loads. Services continue accepting requests without immediately overwhelming downstream systems.
Backpressure introduces additional control by limiting how quickly systems accept traffic during high load periods. Without these controls, request growth becomes difficult to manage once latency increases.
The table below highlights how resilience decisions affect production behavior.
Observability becomes equally important during failure scenarios.
Logs explain isolated application problems. Distributed systems require broader visibility. Teams need metrics, distributed tracing, dependency mapping, and request-level latency tracking.
OpenTelemetry and distributed tracing tools became important because teams needed to identify where requests slowed down across multiple services. A latency increase in one dependency may explain failures elsewhere.
In one production environment, an unstable external integration slowed unrelated APIs because multiple services shared execution resources. Monitoring initially pointed toward application performance problems. Distributed tracing revealed dependency bottlenecks earlier in the request path.
This type of failure becomes harder to diagnose as systems grow.
Teams evaluating a transition toward Spring Boot microservices often underestimate the operational maturity required for distributed environments. More services increase deployment flexibility, though debugging and incident response become harder.
Lesson №5: Synchronous dependencies quietly reduce availability
Microservices often look independent in architecture diagrams. Production systems expose a different reality. Many services remain tightly connected because request paths depend heavily on synchronous communication.
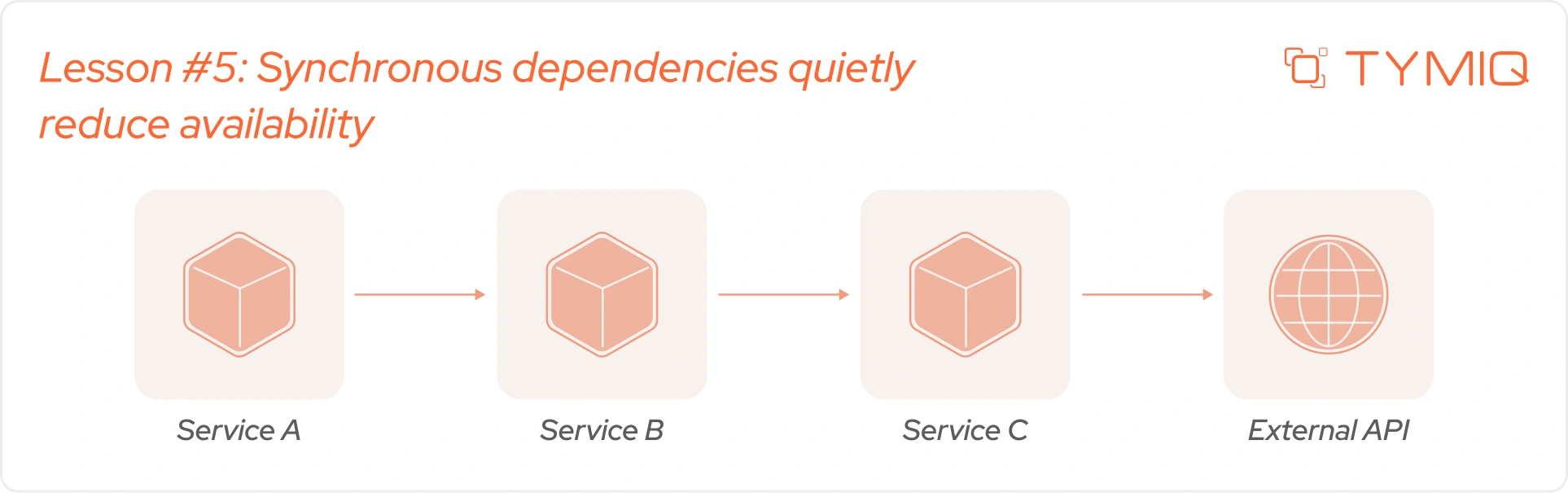
As synchronous dependencies increase, availability starts depending on the slowest service in the request path.
A synchronous request path means every dependency must respond before processing continues. One delayed service slows everything upstream. Timeout coordination becomes harder, threads remain occupied longer, and recovery slows during incidents.
This becomes more visible in high-traffic workflows. A checkout request may depend on pricing, inventory validation, payment authorization, fraud scoring, and shipping calculations before completion. Small delays accumulate across the request path, reducing throughput and increasing timeout pressure.
The architectural consequence appears quickly.
Services deploy independently, though runtime behavior starts resembling a distributed monolith because availability depends on tightly coordinated responses across dependencies. This became a recurring concern in Spring Boot real project environments where service boundaries expanded faster than resilience controls.
Several systems improved reliability after moving selected workflows toward asynchronous communication. Kafka-based event streams reduced pressure on request paths where immediate responses were unnecessary. Notifications, analytics, recommendation updates, and reporting shifted toward event-driven processing, which reduced blocking between services.
These changes introduced tradeoffs. Event-driven systems require stronger observability, clearer ownership of failed events, and more discipline around eventual consistency. Payment authorization and authentication flows still benefited from synchronous communication because immediate responses mattered.
One practical decision framework helped guide architecture conversations:
Spring Boot offers strong tools for distributed systems. Availability still depends on the architecture choices teams make across request paths and service boundaries.
What matters most in high-availability Spring Boot microservices

After working with high-availability Spring Boot microservices across enterprise environments, several recommendations proved consistently valuable. Projects such as Swissphone and Conrad reinforced the same conclusion: reliability problems rarely originate in Spring Boot itself. Stability depends on architecture decisions, dependency management, and operational discipline.
Treat observability as part of the architecture
Logs stop being sufficient once requests move across multiple services. Distributed systems require request tracing, latency visibility, dependency mapping, and actionable metrics from the beginning.
Introduce observability before traffic grows. Teams benefit from distributed tracing, dependency-level monitoring, and clear service health indicators early in development rather than after incidents begin.
Test failure scenarios, not only performance
Load testing measures throughput. High availability depends on how systems behave during instability.
Simulated dependency failures often reveal issues that remain invisible during performance testing:
- inconsistent timeout budgets
- overloaded executors
- retry amplification
- weak recovery assumptions
Include resilience testing early. Dependency outages, delayed responses, and degraded infrastructure often expose production risks before customers encounter them.
Limit synchronous dependencies where latency tolerance exists
Synchronous communication works well for workflows requiring immediate responses. Availability decreases when every request depends on tightly coordinated downstream services.
Keep payment authorization, authentication, and critical validations synchronous when response time matters. Move notifications, reporting, analytics, and background updates toward event-driven processing where delayed consistency is acceptable.
Build resilience before traffic forces the issue
Feature delivery often receives priority during early development. Recovery behavior becomes harder and more expensive to improve after systems accumulate dependencies and operational complexity.
Recommendation:
Treat failover planning, timeout coordination, retry policies, and graceful degradation as early architecture decisions rather than later optimizations.
Spring Boot microservices solve scalability and deployment problems. Reliability depends on how deliberately teams prepare for failure before systems reach production scale.
In a nutshell
Spring Boot microservices solve real engineering problems. They improve scalability, deployment flexibility, and team autonomy. They also introduce new operational risks once systems grow.
Over the years, we’ve seen the same themes repeat across high-availability systems: failover matters early, retries need limits, synchronous dependencies add hidden fragility, and resilience works best when built into the architecture from the start.
If you are working through reliability, scalability, or microservices architecture challenges, contact us to discuss what could work best for your platform.




.svg)


